

Hello! Our clients have increasingly expressed interest in the spatial aspects of digitalization. To cater to this demand, we will be regularly posting related content. We aim to simplify these complex concepts and open new avenues for our clients to benefit from. We highly value your feedback and interaction with our posts. This is intended for solution architects and product managers. If you happened to miss our previous posts, they are here and here. This comprehensive case study is divided into a detailed, step-by-step narrative spanning two parts. You are currently reading Part 2, and Part 1 can be found here. This is written with a step-by-step approach and aims to engage software professionals. We recognize the detailed nature of the content might make for a longer read, and we appreciate your patience. In the write-up, we'll address the reader as 'you'’ assuming you're either a software engineer, a GIS back-end developer, or a front-end developer. We will present suggested software names and their logos, and at times, we may capitalize, bold, or italicize these software names, but please note we may not always be consistent.
Case Study: Using Geographic Information System (GIS) to Map Property Values and Assess Property Taxes
A Software Architect’s Exploration of Best Practice Workflow for Open Source GIS Software and SDI-Considerations
The purpose of this case study is to apply the workflow/worksheet approach mentioned in a previous post to a real-life scenario in the field of municipal finance, specifically focusing on the collection of property taxes using Geographic Information Systems (GIS). GIS technology plays a crucial role in accurately assessing and determining the value of properties within a particular jurisdiction, ensuring a fair distribution of the tax burden among property owners. By integrating GIS data with property tax systems, governments can enhance the accuracy, efficiency, and transparency of the property tax assessment and collection process. This integration enables effective analysis and visualization of spatial information, including property boundaries, land use, zoning, and other pertinent data. Such comprehensive analysis allows assessors to precisely identify and evaluate properties, considering location, amenities, proximity to services, and market conditions. In this post, we will follow the ten-step process outlined in the previous post, displayed below.
Reading Time: 30 min.
Emphasizing Open-Source GIS Software: In exploring GIS application development, we pay special attention to open-source GIS software. Here, we'll delve into various open-source GIS tools, highlighting their unique features and uses. In our discourse, these tools may be highlighted in various ways. Sometimes, they'll be featured as standalone bullet points, elaborating on their specific functions and advantages. Other times, their logos may be displayed to enhance recognition and familiarity. Occasionally, they may be mentioned within the text, seamlessly integrated into the discussion, or highlighted in bold for emphasis. We may not follow a consistent pattern in highlighting these tools. Still, one thing is certain: we bring attention to them and explain how they're employed in the process of GIS application development. Open-source GIS tools form the backbone of many successful applications, and understanding their use and implementation is key to creating effective, reliable, and efficient GIS solutions.
In the broad domain of municipal finance, the application of GIS technology serves myriad essential purposes. Examining a single facet in this case study, we focus on the role of GIS in facilitating property valuation and taxation. By considering diverse spatial factors, GIS ensures taxation is calibrated to a property's fair market value. This leads to a more balanced distribution of property taxes among owners, with properties of similar characteristics in comparable locations fairly taxed. GIS technology bolsters efficiency by automating data integration, analysis, and visualization within the tax assessment and collection processes. It reduces manual effort and empowers assessors with spatial data-driven insights. Another benefit is GIS's transparency by visually depicting property data, demystifying tax calculations for property owners, and enabling them to verify the factors used in assessments. Furthermore, GIS assists in effective land management, empowering authorities to monitor land use, record changes, and strategize future developments. Employing GIS for property tax collection is ultimately directed towards instituting a fair and efficient tax assessment and collection system, enhancing accuracy, improving processes, ensuring transparency, and contributing to effective land governance.

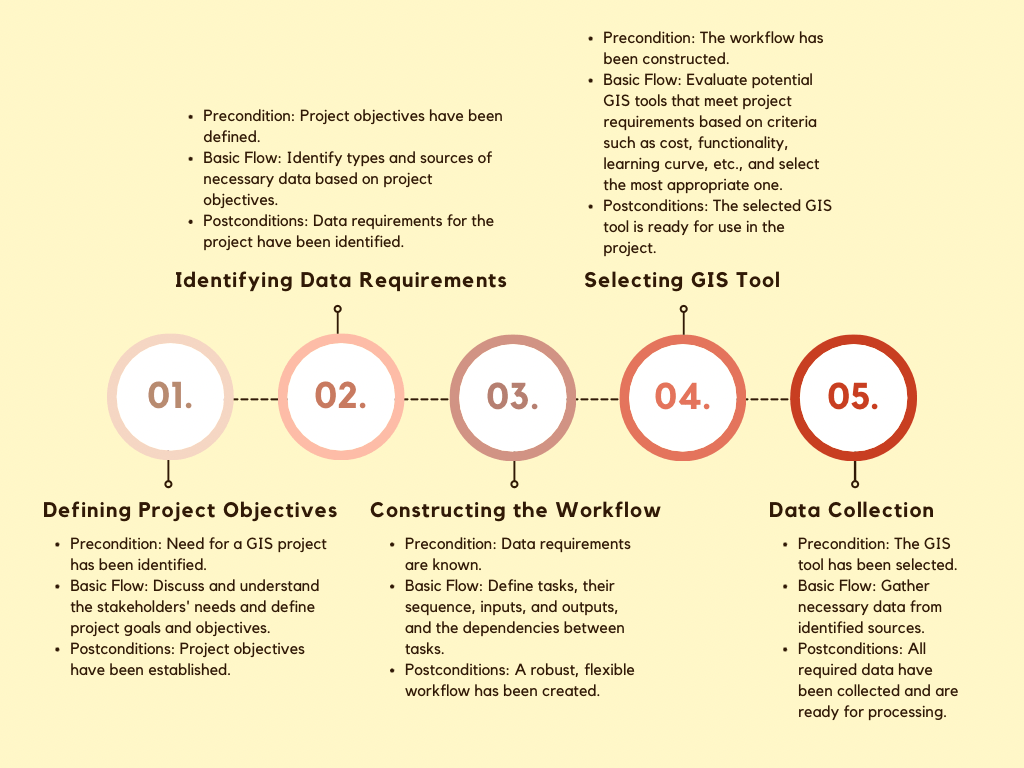
STEP#3: Constructing the Workflow
Developing a workflow for a GIS solution is crucial, particularly when integrating several open-source software tools. This process helps understand the sequence of operations, enhances efficiency, and eliminates redundancy. A workflow serves as an organizational tool, enabling the identification of required tasks and their dependencies and facilitating precise time and resource allocation. Importantly, it acts as a measure of quality control, ensuring all procedures are adhered to correctly, thereby boosting the reliability of results. Furthermore, a well-defined workflow assists in the documentation of processes, allowing clear communication among team members and stakeholders, and ensures reproducibility, a key aspect in GIS applications. When utilizing open-source software, the importance of a well-structured workflow is heightened due to the unique challenges these tools introduce. Different open-source software can have compatibility issues when integrated, making a well-defined workflow essential to detect and resolve these problems early. Open-source tools might also depend on specific software versions or libraries, so clearly defining dependencies within the workflow ensures the correct versions are used. Each software has its learning curve, and understanding where each tool fits into the workflow enables effective planning and resource allocation. These open-source tools often require manual integration, which can be planned and tested thoroughly within a comprehensive workflow. Frequent updates to open-source software can alter how the software functions or interacts with other tools, making a robust workflow necessary for managing these changes without disrupting the project. Furthermore, a detailed workflow assists in maintaining quality control and reproducibility, which is particularly crucial when utilizing open-source software. Lastly, having a well-defined workflow aids in communicating issues more effectively when seeking help from the supportive open-source community, thus ensuring the smooth operation of the GIS project.
1. Designing Metadata and Schema Structure—setting up the structure of your geodatabase, defining how different datasets will interact, and establishing standards for metadata. This step ensures data organization, consistency, and accessibility throughout the GIS application.: Sometimes, this is included in the workflow's data requirements step (STEP#2), but we prefer to do it as part of the workflow because it can involve software use and more definition. The first step involves designing the metadata and schema structure, which entails setting up the structure of the geodatabase—a database designed to store, query, and manipulate geographic information and spatial data. It's a type of database that integrates geographic data (spatial data), attribute data, and spatial relationships between different datasets, providing a more robust framework for managing spatial data compared to traditional flat file storage methods, defining how the different datasets will interact, and establishing standards for metadata. This includes defining the data structure, where you determine what tables you'll need, the attributes they'll have, and their interrelations using PostgreSQL and PostGIS. Following this, you must establish metadata standards, with INSPIRE and ISO 19115 commonly used for geospatial data. After deciding on the standards, creating metadata templates based on the chosen standards becomes crucial. Documenting your data collection and entry procedures also forms a significant part of the workflow. The last part of this stage involves implementing data quality controls by establishing procedures to check your data's quality. The output of this process is a structured geodatabase, comprehensive metadata standards, and data collection and quality control procedures. When referring to "services" or "institutions" in this context, it is generally meant to refer to the organizations or systems that either provide the data you are working with or will be utilizing the data you are managing. For instance, if you're working in the municipal finance data field, "selected institutions" could be government agencies responsible for land planning and use and local government and tax authorities. The "scheme of service" from these institutions can refer to the specific protocols, standards, or methods these organizations use to collect, store, and share data. Understanding these can help you design your geodatabase, metadata standards, and data collection and quality control procedures to be compatible with these institutions. This can be crucial for interoperability—the ability of diverse systems and organizations to work together efficiently. Emphasize the importance of a well-defined workflow to detect and resolve compatibility issues and manage software dependencies using open-source tools.
In summary:
Define the Data Structure: Abiding by ISO 19107 - Geographic information - Spatial schema, the first step is to define the structure of your geodatabase. To do this, you must fully understand your existing data, which can be achieved through schematic mapping. This mapping should visually represent how your current data is structured and highlight any potential areas of inefficiency or redundancy. This step also involves generating periodic reports, which help monitor the state of your data and provide insight into how it's changing over time, facilitating iterative improvements in your data structure. Also, this stage includes a schematic mapping of the scheme of service of selected institutions. By understanding these services, you can identify gaps in your data or potential new data sources. By identifying these, you're not only defining but also refining the structure of your geodatabase. The open-source tool for schematic mapping in this step is QGIS. The open-source relational database PostgreSQL and the geospatial extension PostGIS are the chosen tools for defining the database structure.
Establish Metadata Standards: Leveraging ISO 19115 - Geographic Information - Metadata, decide on the metadata standards to use. These standards will guide the formatting and classification of your geospatial data. The choice of standards should also consider the schematic mapping of the scheme of service of relevant institutions. Understanding these various service schemes gives you a clear view of what metadata standards would best suit your needs and ensure effective communication and data interoperability with these institutions. GeoNetwork, a comprehensive catalog system for managing spatially referenced resources, is an open-source tool for managing metadata by established standards.
Create Metadata Templates: Utilizing ISO 19110 - Geographic information - Methodology for feature cataloging, create metadata templates that adhere to your chosen standards. Part of this step involves developing a conceptual schema for digital information dashboards. This conceptual schema acts as a blueprint, showing how data will be organized and presented on your dashboards. This organization must align with the metadata templates, ensuring that the data is well-structured and can be effectively visualized for end users. Metatools, an extension of QGIS, is the open-source tool recommended for creating and managing metadata templates in this step. For designing digital dashboards based on metadata templates, Apache Superset, an open-source data exploration and visualization platform, is to be used.
Document Data Collection Procedures: Following ISO 19157 - Geographic information - Data quality, document your data collection and entry procedures. By understanding the scheme of service of relevant institutions, you can tailor your data collection procedures to harmonize with these services. These documented procedures should be collated into a comprehensive handbook describing your approach to digitizing non-digital data. This handbook serves as a go-to resource, ensuring consistency in data handling practices and offering clear guidance to all involved in the data collection process. LibreOffice Writer, an open-source word processor, will create comprehensive handbooks and document data collection procedures. The open-source mobile app, Input, based on QGIS, is recommended for systematic data collection as per established procedures.
Implement Data Quality Controls: Implement robust data quality control measures based on ISO 19138 - Geographic Information - Data Quality Measures. This involves defining a quality assurance approach to digitalizing existing non-digital data, ensuring the digitized data retains its accuracy and reliability. Moreover, these measures should extend to checking data resulting from periodic reports, contributing to an ongoing effort to maintain the integrity of the data in your geodatabase. Furthermore, organize hands-on training sessions for your team to understand and execute these quality control procedures effectively. This not only increases the proficiency of your team but also helps in maintaining consistent, high-quality data across your geodatabase. QGIS, with its built-in functionalities for data cleaning and quality control, is the tool of choice in this step. Moodle, a widely used open-source learning management system, is the chosen tool for creating and managing hands-on training modules to ensure the effective implementation of quality control procedures.
Do: Take the time to plan and design the geodatabase structure carefully. Consider scalability and flexibility to accommodate future data updates and changes. Invest time and resources in designing a well-structured geodatabase and establishing clear, comprehensive metadata standards. This will save you a lot of trouble down the line.
Don't: Neglect the importance of metadata. Well-documented metadata improves data discoverability, ensures data integrity, and facilitates data sharing. Don't neglect data quality controls. Regular checks for data quality are crucial for maintaining the accuracy and reliability of your geodatabase.
Output: A well-defined data structure, established metadata standards, metadata templates, documented data collection procedures, and implemented data quality controls. These outputs will be the foundation for effectively organizing and managing the GIS data.
Don’t forget:
Step 1.1: Define Data Structure—define the structure of your geodatabase. Determine what tables you need, their attributes, and how they relate. Ensure your structure will support all the data you need for your property assessments.
Step 1.2: Establish Metadata Standards—decide on the metadata standards you will use. INSPIRE and ISO 19115 are commonly used standards for geospatial data. Your metadata should include information about when and how the data was collected, who collected it, what geographic area it covers, and any restrictions on its use.
Step 1.3: Create Metadata Templates—create templates for your metadata based on your chosen standards. This will ensure consistency across all your datasets.
Step 1.4: Document Data Collection Procedures—document your data collection and entry procedures. This will help ensure your data is collected and entered consistently and accurately.
Step 1.5: Implement Data Quality Controls—establish procedures for checking the quality of your data. This could involve regular checks for errors in data entry, consistency across different datasets, and checks to ensure that your data matches reality.
2. Data Collection and Digitization: In this step, you will collect spatial and non-spatial data from various sources. The accuracy and comprehensiveness of your data collection efforts are essential for accurate property assessment and tax calculations. Highlight the need for thorough planning and testing within the workflow to address challenges that may arise when integrating different open-source software components.
Identify Data Sources: Identify the sources from which you will collect data. This can include local government databases, open-source data platforms, public records, surveys, or field data collection.
Collect Spatial Data: Collect the necessary spatial data for property assessment. This may involve acquiring parcel boundaries, future development plans, satellite images, topographic data, land use data, road networks, environmental data, and other relevant spatial information. QGIS is commonly used for handling and processing spatial data. It provides various data collection, analysis, and validation tools.
Collect Non-Spatial Data: Collect the non-spatial data pertinent to property assessment. This can include information such as structural characteristics of properties, rental history, ownership details, sale history, tax records, local market data, zoning regulations, environmental efficiency ratings, disaster history, crime statistics, liens and judgments, and other relevant data. This is a foundational step. If you have physical paper records, you must manually input this data or use scanning and Optical Character Recognition (OCR) technology to digitize the records. Check the digitized data for any errors or discrepancies. Data in Excel or other digital formats can be compiled for easier processing in the next steps. For OCR, you can use tools like Adobe Acrobat or Tesseract. You can use Excel or a similar spreadsheet tool to organize digital data. Tools like spreadsheets or databases (e.g., Microsoft Excel or PostgreSQL) can also be used for managing and cleaning non-spatial data.
Data Cleaning and Validation: Conduct data cleaning and validation procedures after collecting data. Remove duplicate entries, correct errors, and fill in missing values. Validate the accuracy and integrity of the data by cross-referencing different data sources and conducting quality control checks.
Do: Ensure data accuracy and completeness through thorough data collection efforts. Validate the collected data against reliable sources and employ quality control measures. Don't: Overlook the importance of data cleaning and validation. Inaccurate or incomplete data can lead to erroneous assessments and calculations.
Don't: Rely solely on a single data source. Cross-reference and validate data from multiple sources to ensure accuracy and completeness. Using diverse and reliable data sources enhances the reliability of your property assessments and tax calculations.
Output: A comprehensive collection of spatial and non-spatial data relevant to property assessment and tax calculations. The collected data will serve as the basis for subsequent analysis and processing steps in the GIS application.
3. Map Digitization/Building Footprints (if needed): We will examine two methods here.
METHOD#1: Machine Learning-Based Updating of Zonal Map Information (ZMI) Building Footprints Using Very High Resolution (VHR) Satellite Imagery: This complex method is a subset of the wider remote sensing and GIS disciplines. Substantive model training and calibration are required to effectively implement automatic feature extraction and machine learning classification, which can be rigorous. Manual digitization, while accurate, is labor-intensive and may prove impractical for larger regions. Yet, it's worth noting that the precision of the final building footprints directly influences their value in subsequent analyses or planning activities, exemplified in this municipal finance case study, amongst other use cases. Accuracy can vary significantly depending on many factors, including the quality of the VHR imagery, the machine learning model used, the features selected, the quality of the training data, and how well the model is trained. With a well-designed process and sufficient training data, achieving high accuracy is possible.



Image Procurement: Obtain satellite imagery for your area of interest. While Sentinel-2 data from the European Space Agency and U.S. Landsat data are good sources of satellite imagery, for Very High Resolution (VHR) data, you might need to consider commercial providers like Maxar's WorldView or Airbus's Pleiades.
Image Preprocessing: For this step, we can use QGIS to create, edit, visualize, analyze, and publish geospatial information. Use QGIS for orthorectification, radiometric correction, and pan-sharpening. GDAL (Geospatial Data Abstraction Library) also provides command-line tools for these tasks.
Machine Learning Feature Extraction: This process is more complex and often involves machine learning for automatic feature extraction. OpenCV can be used for edge detection for building footprints, while scikit-learn or TensorFlow can be used for more advanced machine learning classification tasks. However, this will involve training a model, which requires labeled data (i.e., examples of what buildings look like in your VHR imagery). Let’s break this down further—Remember, feature extraction from VHR imagery is a challenging task that requires a good understanding of image processing and machine learning concepts. There's also a degree of trial and error in tuning your model and selecting the right features. The better your trained model, the better your final building footprints will be.
Image Segmentation: This is the first step, where you divide your VHR image into multiple segments, each containing pixels with similar characteristics. This step is crucial in identifying potential areas where a building might exist. OpenCV's segmentation functions can be utilized for this purpose. Here, techniques such as color-based segmentation or texture-based segmentation can be applied.
Data Labeling: You'll need labeled data to train a machine-learning model. This means you will need examples of building footprints (positive cases) and examples of non-building areas (negative cases). This can be a manual process, where you or a team outline building footprints in a portion of your VHR imagery and label them accordingly.
Feature Selection: Now, you must decide what features to feed into your machine learning model. This could include color information, texture information, shape descriptors, or other computed features like edge detection results. You might also use OpenCV for this task, which offers functionality for edge detection, color histograms, and other common image processing tasks. Python's libraries, like NumPy and pandas are excellent for data manipulation and feature selection. With OpenCV, which can calculate various image characteristics, you could generate a rich feature set for your machine-learning model.
Model Testing and Evaluation: Split your data into training and test sets. The model is trained on the training set and then evaluated on the test set. You would compare the model's predictions to the actual labels in your test set to determine the model's accuracy. If the model isn't accurate enough, you might need to return to the previous steps and adjust your feature selection and model parameters or gather more labeled data.
Model Selection and Training: Select an appropriate machine learning model. If you have enough labeled data and computational power, a Convolutional Neural Network (CNN) might be a good option, as they are particularly well-suited to image classification tasks. Both TensorFlow and scikit-learn have CNN capabilities. You would then train your model on your labeled data. This involves feeding in your features (building descriptors) and labels (whether each example is a building) and allowing the model to learn their relationships. Scikit-learn provides many tools for model evaluation, including functions to calculate various performance metrics (like precision, recall, F1-score, ROC AUC score) and to generate confusion matrices. If you're using TensorFlow or Keras for your model, they also have built-in functions for model evaluation.
Model Application for Feature Extraction: Once you have a model performing well on your test data, you can use it to predict building footprints in new, unlabeled VHR imagery. This involves applying your segmentation and feature selection steps to the new image, then feeding these features into your trained model. The output should be a prediction for each segment of whether it contains a building or not. This would be done using the same library as your machine-learning model. So if you've trained your model in TensorFlow or Keras, you'd use that library to load your trained model and make predictions on your new data.
Post-Processing: Finally, your model's output will likely require some post-processing to convert it into a useful form for your GIS. For example, you might need to convert your building predictions into a polygon format or filter out small objects falsely classified as buildings. QGIS or GDAL can be useful for this step as they offer extensive tools for manipulating geospatial data—QGIS can be used to view and manually verify the results and export them into the desired format.
Comparison and Updating: The newly extracted building footprints are compared with the previous building footprint data from ZMI. This could involve overlaying the two datasets and looking for discrepancies. Any new buildings shown in the VHR imagery that aren't in the ZMI data would be added, and any buildings that no longer exist would be removed from the dataset. PostGIS could be used to compare and update the ZMI building footprint data with the newly extracted building footprints. Overlaying the old and new datasets allows you to inspect the changes visually, but it could be arduous for large areas. That's where PostGIS can be particularly useful. PostGIS provides powerful functions for spatial queries. For example, you can use it to automatically detect discrepancies between the two datasets, identifying areas where a new building footprint in the VHR data does not overlap with any footprint in the ZMI data (indicating a potential new building) or where a footprint in the ZMI data does not overlap with any footprint in the VHR data (indicating a potential demolished building). Sometimes, this process may not be perfect and could result in false positives or negatives. For instance, buildings might be missed or falsely identified if the VHR imagery isn't unclear or the machine learning model makes mistakes. In such cases, manual verification should also be done as a double-check (next step).
Quality Assessment and Accuracy Checking: Once the updates are made, performing a quality check is important. This might involve taking a sample of the buildings and manually verifying that they exist and are correctly delineated or compared to another independent data source.
Ground Truthing: Field verification may occasionally play a vital role in the quality assessment and accuracy checking stage for several reasons. First, direct on-the-ground observations, known as "ground truthing," can affirm that features recognized in VHR imagery and processed by the machine learning model do represent actual buildings, helping to enhance the model's accuracy. Second, field checks can pinpoint systematic errors or issues with the satellite imagery or machine learning model, such as consistently misclassified buildings or materials. Lastly, feedback from field checks can contribute to refining and improving the machine learning model, potentially involving retraining on a more balanced dataset, tweaking model parameters, or modifying the feature selection process. However, field verification may not always be feasible or necessary, particularly when dealing with expansive or remote areas. The process can be costly and time-consuming, and alternative accuracy assessment methods might be more practical in some cases, such as comparison with other independent datasets like aerial photos or existing maps. Also, checking every building might not be possible, suggesting a likely need for a statistical sampling approach. Crucially, the goal of this process is not necessarily absolute accuracy, which is nearly impossible, but to develop a sufficiently accurate dataset for its intended application and comprehend the limitations and potential sources of error in the data. Open-source mobile GIS applications are instrumental for ground truthing and in-field verification of building footprint data. They allow for the visualization, capturing, and direct editing of geospatial data on mobile devices in the field. Options include QField, a field mapping app for Android that is a QGIS companion and can be used to verify and edit building footprints against actual buildings, and Input, a similar app available on Android and iOS. These apps, alongside open-source GPS logging apps, facilitate data syncing between your mobile device and the main GIS system, thus seamlessly incorporating field changes into the main dataset. A good base map, like OpenStreetMap, is also crucial for field navigation. Open Data Kit (ODK) and KoBoToolbox can be employed in building footprint validation to design survey forms for verifying the presence and characteristics of each building, take photos, and note any issues, which can then be synced with your main database for further analysis and footprint updates. While these mobile GIS applications offer significant advantages, it's important to acknowledge potential limitations. For instance, a stable and strong internet connection might not always be available, especially in remote areas.
Integration and Dissemination: Once you have your final, updated dataset, it must be integrated with your existing GIS infrastructure and possibly shared with other users or stakeholders. PostGIS can be used for storing, manipulating, and analyzing spatial data. Integrating your GIS infrastructure allows sophisticated management and querying of your updated dataset.
Two different examples from real applications stand out. First, The European Space Agency (ESA) has done significant work in this European area. They have numerous projects involving satellite imagery for various purposes, including urban planning and development. Their AI4EO (Artificial Intelligence for Earth Observation) program leverages machine learning and VHR satellite data from their Sentinel satellites for various applications, potentially including building footprint extraction. In Africa, a notable example would be the work done by the Zanzibar Mapping Initiative in Tanzania. In collaboration with various partners, they used drone imagery (which offers a similar resolution to VHR satellite imagery) to create a high-resolution map of the islands of Zanzibar and Pemba, including building footprints. This involved both manual digitization and automated methods. While not the same as the method described, it demonstrates the potential of these techniques when applied with local knowledge and community involvement.
We would add that this method is common in urban planning and development, disaster response and management, and environmental studies—in urban planning, up-to-date building footprint data aids in designing transportation systems, managing utilities, and monitoring housing and real estate trends. For disaster response, analyzing satellite imagery can expedite the identification of damaged buildings, enabling efficient allocation of emergency resources. In environmental studies, tracking urban sprawl and its environmental impact becomes feasible with current building footprints; the adoption of this method stems from its scalability, which provides a swift alternative to time-consuming manual digitization, especially for larger areas. Additionally, satellite imagery offers a recent snapshot of the Earth's surface for more frequent updates than traditional survey methods. Machine learning models also ensure more consistent, objective results than manual methods prone to human error. Lastly, once the initial development and training of the machine learning model are done, this method proves to be cost-effective, capable of processing vast data volumes at a relatively low cost compared to manual surveying or digitization. However, it's imperative to acknowledge the complexity of achieving high accuracy in building footprint extraction from VHR imagery with supervised machine learning, necessitating significant investment in data, time, and technical expertise.
METHOD#2: Digitizati9n of Maps: In this step, you will focus on digitizing physical parcel maps, converting them into digital format, and incorporating them into GIS. Map digitization enables the accurate representation and analysis of spatial data. Emphasizing the significance of a robust workflow for managing changes in open-source software and ensuring manual integration must be thoroughly planned and tested.
Obtain Physical Parcel Maps: Acquire the physical parcel maps that contain the necessary property boundary information. These maps can be obtained from local government offices, survey records, or other relevant sources.
Digitize Maps: Scan the physical parcel maps to create digital images. Use a scanner or a high-resolution camera to capture clear and detailed images of the maps.
Import Scanned Map Images into GIS: Bring the scanned images into GIS using QGIS. Create a new project and import the scanned images as raster layers.
Digitize Parcel Boundaries: Use the digitizing tools available in QGIS to trace the parcel boundaries directly on the scanned map images. Ensure accurate and precise digitization by zooming in and using reference points for alignment.
Georeference Parcel Layer: Georeference the digitized parcel boundaries by aligning them with real-world coordinates. This involves identifying control points on the digitized map and referencing them to known coordinate systems or using satellite imagery for spatial reference.
Determining Control Points for Georeferencing: This involves identifying easily identifiable features on the digitized map and matching them with corresponding features on a reference map or satellite imagery—here's an overview of the process: (1) Identify Control Points: Look for distinct features on the digitized map that can be easily identified and located on both the digitized map and the reference map or satellite imagery. Examples of control points could include road intersections, prominent landmarks, or identifiable buildings; (2) Select Reference Map or Satellite Imagery: Obtain a reliable reference map or high-resolution satellite imagery that covers the same geographic area as the digitized map. The reference map or satellite imagery should have accurate coordinate information; (3) Locate Control Points: Locate the identified control points on both the digitized map and the reference map or satellite imagery. This can be done visually by matching the features or using geographic coordinates, if available; (4) Measure Control Point Coordinates: Use QGIS to measure the coordinates (latitude and longitude or projected coordinates) of the control points on both the digitized map and the reference map or satellite imagery. This can be done by clicking on the respective locations and extracting the coordinates; (5) Match Control Points: Compare the measured coordinates of the control points on the digitized map with the corresponding control points on the reference map or satellite imagery. Identify any discrepancies and adjust the digitized map accordingly, and (6) Georeference the Digitized Map: Once you have identified and matched several control points, use the georeferencing tools in QGIS to apply the necessary spatial transformation to align the digitized map with the reference map or satellite imagery. This will ensure that the digitized parcel boundaries are accurately placed in real-world coordinates. It's important to note that the accuracy of the georeferencing process depends on the quality and reliability of the reference map or satellite imagery and the precision in identifying and measuring the control points. Using high-resolution satellite imagery or reference maps with accurate coordinate information will enhance the accuracy of the georeferencing process. Regenerate response
Do: Digitize parcel boundaries accurately to ensure precise spatial analysis and property assessments.
Don't: Rush the digitization process. Pay attention to detail and accuracy when tracing parcel boundaries and georeferencing the maps.
Output: Digitized parcel boundaries in the form of vector layers within QGIS. These digitized maps will serve as the basis for property assessment and tax calculations, allowing for spatial analysis and visualization.
4. Geodatabase Creation and Data Import—Integration of Spatial and Non-Spatial Datasets within the Geodatabase: In this step, you will import both the spatial and non-spatial data into the Geodatabase and establish relationships between different datasets. Data integration allows for efficient management and analysis of the collected data. PostgreSQL and PostGIS are commonly used for data integration. PostgreSQL provides a robust relational database management system, while PostGIS adds spatial capabilities to handle spatial data effectively. Highlight the importance of a well-structured workflow for maintaining quality control, reproducibility, and managing updates to open-source software without disruption.
Import Spatial Data: Use PostgreSQL and PostGIS to import the spatial data into the geodatabase. This includes importing digitized parcel boundaries, satellite images, topographic data, road networks, environmental data, and other relevant spatial datasets. Create appropriate tables and define the necessary attributes to store the spatial data.
Import Non-Spatial Data: Import non-spatial data, such as property characteristics, ownership details, rental history, tax records, and other relevant information. Use PostgreSQL to create tables and define the appropriate fields to store the non-spatial data.
Establish Relationships: Identify the relationships between different datasets within the geodatabase. Establish primary and foreign key relationships to link the spatial and non-spatial data tables. This will enable efficient querying and analysis of the integrated data.
Validate Integrated Data: Perform data validation checks to ensure the accuracy and integrity of the integrated datasets. Validate spatial and attribute data by cross-referencing and comparing with external sources. Address any discrepancies or errors identified during the validation process.
Do: Ensure the data integration maintains data integrity and establishes relationships between related datasets. Ensures data types and structures match your needs. Keep track of your SQL commands for reproducibility. Clean and format your address data before geocoding. Use accurate and up-to-date spatial data. Cross-reference multiple sources for best results.
Don't: Neglect data validation and quality checks. Accurate and reliable data is crucial for meaningful property assessments and tax calculations. Don't: Ignore potential errors in geocoding—accuracy is critical. Don't assume spatial data will align perfectly. Always check and adjust as necessary.
Output: A geodatabase with integrated spatial and non-spatial datasets, including linked tables with established relationships. This integrated dataset serves as the foundation for subsequent analysis and calculations in the GIS application.
Don’t Forget:
Geodatabase Creation and Data Import
Step 4.1: Install PostgreSQL and the PostGIS extension on your server.
Step 4.2: Create a new geodatabase within PostgreSQL.
Step 4.3: Use SQL commands to structure your data within the geodatabase. This may include creating tables and defining relationships.
Step 4.4: Import your digitized data into the geodatabase, matching the data to the correct tables and fields.
Step 4.5: Review the data in the geodatabase to ensure it has been imported correctly.
Geocoding
Step 4.6: Identify data that includes property addresses.
Step 4.7: Format the address data for compatibility with geocoding services.
Step 4.8: Use geocoding services like Google Maps Geocoding API or open-source tools like Nominatim to convert addresses into geographic coordinates.
Step 4.9: Import the geocoded data back into your geodatabase.
Step 4.10: Perform quality checks to verify the accuracy of the geocoding.
Spatial Data Integration
Step 4.11: Identify and gather spatial data relevant to your project, such as parcel boundaries, satellite images, and topographic data.
Step 4.12: Import the spatial data into QGIS.
Step 4.13: Overlay the geocoded address data onto the spatial data in QGIS.
Step 4.14: Adjust the spatial data to ensure alignment with the geocoded addresses.
Step 4.15: Export the aligned spatial data from QGIS and import it into your geodatabase.
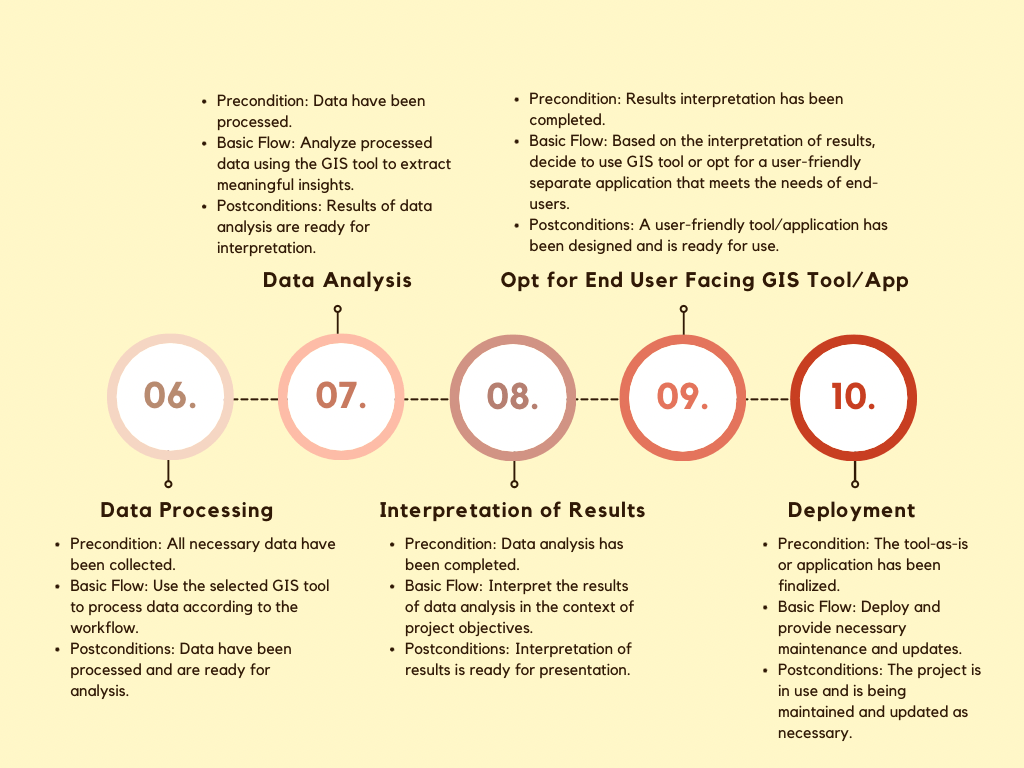
5. Data Analysis: In this step, you will analyze the integrated spatial and non-spatial datasets within the geodatabase. Data analysis allows for deriving insights, identifying patterns, and making informed property assessment and tax calculation decisions. QGIS provides a wide range of tools for spatial analysis, including buffering, spatial joins, and proximity analysis. It also offers advanced visualization options to aid in interpreting and communicating the analysis results.
Define Analysis Goals: Clearly define the goals and objectives of your data analysis. Determine the specific questions you want to answer or the insights you want to gain from the data.
Execute GIS Analysis: Utilize the analytical capabilities of QGIS to perform spatial analysis on the integrated datasets. Apply analysis techniques, such as buffering, spatial joins, proximity analysis, and spatial clustering, to derive meaningful information.
Validate Analysis Results: Validate the results of your data analysis to ensure accuracy and reliability. Cross-reference the analysis outcomes with external sources, perform statistical checks, or consult domain experts to verify the findings.
Interpret Analysis Results: Interpret the analysis results in the context of property assessment and tax calculations. Identify trends, patterns, and relationships between variables that impact property values or tax rates. Extract meaningful insights to support decision-making.
Communicate Findings: Effectively communicate the findings of your data analysis. Prepare visualizations, charts, or reports that summarize the results and make them easily understandable for stakeholders and decision-makers.
Do: Clearly define your analysis goals and objectives to guide your data analysis process. Validate and interpret the results carefully to ensure accurate and meaningful insights.
Don't: Rely solely on automated analysis without considering domain knowledge and validation. Interpret the analysis results in the context of property assessment and tax calculations.
Output: Analysis results and insights derived from the integrated spatial and non-spatial datasets. These findings serve as the basis for informed decision-making in property assessment and tax calculations.
In Step 5, Data Analysis, various analyses can be conducted using the available spatial and non-spatial data. Here are some examples of analyses that can be performed focusing on property information and valuation. These examples demonstrate how data analysis can leverage spatial and non-spatial data to gain insights into property valuation factors and make informed decisions. Various software tools like QGIS, R, or Python libraries such as Pandas and Matplotlib can be utilized for conducting these analyses.
Spatial Analysis:
Proximity Analysis: Determine properties' proximity to amenities such as schools, parks, shopping centers, or hospitals. Analyze how proximity influences property values.
Buffer Analysis: Create buffers around properties to assess the impact of certain features, such as road networks or environmental factors, on property values.
Spatial Clustering: Identify clusters of properties with similar characteristics or values to understand localized patterns in property valuation.
Overlay Analysis: Overlay different spatial datasets (e.g., land use, flood zones) to identify areas with specific characteristics that may influence property values.
Statistical Analysis:
Regression Analysis: Perform regression models to identify factors that contribute to property value variation, such as square footage, number of rooms, age of the building, and proximity to amenities.
Descriptive Statistics: Calculate summary statistics of property values, such as mean, median, and range, to understand the distribution of property values in different areas.
Correlation Analysis: Determine the relationship between property values and other variables, such as land use, proximity to road networks, or environmental factors.
Time Series Analysis: Analyze trends in property values over time to understand market fluctuations and assess the impact of external factors, such as economic conditions or changes in zoning regulations.
Comparative Market Analysis:
Sales Comparison Approach: Compare recent sales data of similar properties in the area to assess market trends and determine property values based on comparable sales.
Market Price Indexing: Develop a market price index using historical sales data to track changes in property values over time and identify areas with increasing or decreasing property values.
Spatial Interpolation: Use spatial interpolation techniques to estimate property values for areas with limited sales data based on nearby comparable properties.
Risk Assessment:
Disaster Risk Analysis: Evaluate the risk associated with natural disasters (e.g., floods, earthquakes) by analyzing historical disaster data and their impact on property values.
Crime Analysis: Examine crime statistics in the area to understand the impact of crime rates on property values and assess the desirability of specific locations.
Liens and Judgments Assessment: Investigate the presence of liens or judgments against properties to evaluate potential risks and their impact on property value.
Data Visualization:
Thematic Mapping: Create maps to visualize property values, land use patterns, proximity to amenities, or other relevant factors.
Heatmaps: Generate heatmaps to illustrate property density, market trends, or other spatial patterns related to property valuation.
Charts and Graphs: Use bar charts, line graphs, or scatter plots to visually represent relationships between property characteristics, market data, and property values.
6. Property Assessment: In this step, you will conduct property assessments based on the available data and methodologies. Property assessment involves determining the market value of properties based on various factors such as size, condition, location, and comparable sales. You can use QGIS, PostgreSQL, and spreadsheets for data analysis and calculations to conduct property assessments. These tools provide functionality for organizing and analyzing property data, performing calculations, and recording assessment results.
Define Assessment Methodology: Determine the assessment methodology that aligns with local regulations and best practices. Consider using the market, cost, or income approaches, depending on the property type and data availability.
Conduct Property Assessment: Apply the chosen assessment methodology to the available data. This may involve analyzing comparable sales, property characteristics, rental history, and other relevant factors. Calculate the assessed value of properties based on the assessment methodology and data analysis.
Validate Assessment Results: Validate the assessment results to ensure accuracy and consistency. Cross-check the calculated assessed values with market trends, expert opinions, or external sources to verify their reasonableness.
Document Assessment Results: Document the assessment results for future reference and transparency. Record the methodology, data sources, key assumptions, and supporting documentation. This documentation is essential for auditing purposes and clearly explains the assessment process.
Do: Follow established assessment methodologies and local regulations to ensure consistency and fairness in property assessments. Document the assessment process and results for transparency and accountability.
Don't: Rely solely on subjective judgment without considering objective data and analysis. Validate the assessment results to maintain accuracy and credibility.
Output: Documented property assessment results, including the assessed values of properties based on the chosen methodology. These results are the basis for calculating property taxes in the subsequent steps.
7. Calculation of Property Taxes: In this step, you will calculate the property taxes based on the assessed property values and the applicable tax rates. Property tax calculations involve determining the amount of tax owed by property owners based on local tax regulations. You can use QGIS, PostgreSQL, and spreadsheets.
Determine Applicable Tax Rate: Determine the tax rate applicable to the jurisdiction in which the property is located. The local government sets the tax rate and represents the percentage of the assessed property value that will be charged as tax. Also, tax rates vary by property type, size, and other specific property characteristics such as size or land use. Per the characteristics, the applicable rate is retrieved from the database, ensuring that they accurately correspond to the relevant property attributes.
Apply Tax Rate to Assessed Property Value: Multiply the assessed value of each property by the tax rate to calculate the annual property tax amount. This calculation determines the tax liability for property owners.
Consider Tax Exemptions and Deductions: Consider any tax exemptions, abatements, or deductions that may apply to certain properties. These exemptions or deductions can reduce the taxable value and lower the property tax amount.
Validate Property Tax Calculations: Validate the property tax calculations to ensure accuracy. Double-check the applied tax rate, assessed values, and any adjustments made for exemptions or deductions.
Register Property Tax Calculations: Register the property tax calculations for record-keeping and future reference. Maintain a clear record of the assessed values, tax rates, exemptions, deductions, and the resulting tax amounts. This documentation facilitates transparency, retrieval and provides an audit trail.
Do: Retrieve and apply the appropriate tax rates from the database based on property size or land use. Establish clear criteria for determining tax rates based on property attributes. Take into account multiple tax rates and apply them accurately to respective properties. Consider and apply tax exemptions or deductions to reduce the taxable value. Maintain detailed documentation of property tax calculations for transparency and future reference.
Don't: Rely solely on generalized tax rates without considering property-specific factors. Overlook the need for accurate and updated tax rate data from the database. Neglect to apply the appropriate tax rates for properties based on size or land use. Disregard the importance of documenting tax rates, exemptions, deductions, and resulting tax amounts. Proceed with property tax calculations without verifying the accuracy of applied tax rates and exemptions.
Output: Calculation of Property Taxes is each property's calculated property tax amounts. This includes the tax amount for each property based on the assessed value, applicable tax rates, and any adjustments made for tax exemptions or deductions. The output can be a report, spreadsheet, or database record that captures the property tax calculations. The output serves as the basis for determining the tax liability and is crucial for further financial planning, tax reporting, and record-keeping purposes.
8. Property Assessment Automation Workflow: Using pandas in the property assessment process can significantly automate and streamline the calculations. Pandas, a powerful data manipulation and analysis library in Python, provides various functionalities that make it well-suited for property assessment tasks. Developing custom scripts will leverage pandas to handle and analyze property data efficiently. With pandas, you can perform the following steps:
Data Integration: Import property data from various sources, such as spreadsheets or databases, into pandas DataFrames.
Data Cleaning and Transformation: Use pandas functions to clean and preprocess the data, handle missing values, standardize data formats, and convert data types if needed.
Analysis and Calculation: Apply the assessment methodology to the property data stored in Pandas DataFrames. Utilize pandas' powerful data manipulation capabilities to perform calculations based on property characteristics, comparable sales, rental history, and other relevant factors.
Assessed Value Calculation: Calculate the assessed values for each property by applying the assessment methodology to the corresponding data using pandas DataFrame operations.
Integration with Property Assessment Database: Store the assessed values back into the property assessment database by directly updating the existing records or inserting new ones.
Do: Utilize QGIS or GDAL to integrate data. Develop custom scripts or workflows using programming languages like Python to automate the property assessment process; leverage pandas and other relevant libraries for efficient data manipulation and calculations. Ensure data accuracy and consistency through thorough data cleaning and transformation techniques. Generate a comprehensive property assessment report documenting the assessed property values, relevant property information, data sources, key assumptions, and supporting documentation.
Don't: Neglect to validate the accuracy of the automated property assessment results against market trends, expert opinions, or external sources. It is important not to overlook the importance of accurately considering property-specific factors and applying the chosen assessment methodology o rely solely on subjective judgment without utilizing objective data and analysis, Don’t disregard the need to document the property assessment methodology, data sources, key assumptions, and any supporting documentation, which is crucial for transparency and future reference or to proceed with property assessment automation without verifying the reasonableness and reliability of the results through proper checks and validation processes.
Output: When automated, the output of the property assessment process includes the assessed values of properties based on the chosen methodology stored in a database, exportable as a report or spreadsheet, or integrated into a wider SDI setup or dashboard system. It serves as a reliable and transparent record of property assessments, providing valuable information for decision-making or utilized for further financial planning, tax reporting, dashboarding, and record-keeping purposes.
9. Tax Automation Workflow: Pandas can also automate tax calculations. By utilizing pandas in the tax calculation process, you can efficiently perform calculations, apply tax rates, and handle exemptions or deductions. Developing custom scripts or workflows using programming can automate the tax calculation process. Utilize pandas to handle and manipulate the necessary data. Here's how pandas can be used in the automation workflow—Pandas' flexible and powerful data manipulation capabilities make them well-suited for these tasks, allowing for efficient and accurate tax calculations.
Retrieve Data: Import the necessary data, including assessed values, tax rates, exemptions, and deductions, into Pandas DataFrames.
Data Cleaning and Transformation: Utilize pandas functions to clean and preprocess the data, handle missing values, standardize data formats, and convert data types if needed.
Tax Calculation: Apply tax rates to the assessed property values using pandas DataFrame operations. Perform calculations to determine the tax amount for each property, considering any applicable exemptions or deductions.
Bulk Calculations: Utilize pandas to perform bulk calculations on the entire dataset, allowing for efficient processing and calculating tax amounts for multiple properties.
Result Generation: Generate a report or store the calculated tax amounts back into the property assessment database or a separate database, depending on your workflow and requirements.
Do: Utilize pandas to automate tax calculations and perform bulk calculations on property data, leveraging its data manipulation capabilities to handle and analyze assessed values, tax rates, exemptions, and deductions. Utilize pandas DataFrame operations to efficiently apply tax rates and calculate tax amounts for each property, implementing data cleaning and transformation techniques to ensure accurate calculations. Additionally, generate reports or store the calculated tax amounts in a database for further analysis and financial planning.
Don't: Overlook the need to ensure data accuracy and consistency before performing tax calculations. Neglect appropriately handling exemptions, deductions, and tax rates within the Pandas workflow. Rely solely on manual calculations without leveraging pandas' computational efficiency. Forget to validate the accuracy of the calculated tax amounts against known tax records or regulations. Disregard storing the calculated tax amounts for future reference and reporting purposes.
Output: When automated using pandas, the tax calculation process includes the calculated tax amounts for each property. These tax amounts are based on the assessed property values, applicable tax rates, and any adjustments made for tax exemptions or deductions. The output can be stored in a database, exported as a report or spreadsheet, or utilized for further financial planning, tax reporting, dashboarding, and record-keeping purposes.

STEP#5 to #8: Data Collection, Processing, Analysis & Interpretation
The workflow described above provided a comprehensive overview of the data collection, processing, analysis, and interpretation— STEPS #5 to #8. Therefore, we will omit to repeat these details here and instead refer back to the detailed workflow description above for information regarding these steps. We will provide a quick summary anyway:
STEP#5: Data Collection
Step 5.1: Identify the sources of data you need to collect. This could be from local government databases, paper records, or other sources.
Step 5.2: For physical data, use scanning tools to create digital images of the documents. Software like Adobe Acrobat can assist with this task.
Step 5.3: Use OCR tools to extract the data from scanned images. Software like Tesseract or Adobe Acrobat can help with this.
Step 5.4: Gather all Excel or CSV files and consolidate them into a manageable format for digital data.
Step 5.5: Perform an initial review of the digitized data for errors or discrepancies. Correct any issues you identify.
STEP#6: Data Processing
Step 6.1: Identify potential issues in the data, such as missing values or inconsistent formats.
Step 6.2: Use SQL in PostgreSQL or the pandas library in Python to clean and format your data.
Step 6.3: Perform data integration tasks like linking tables based on common fields or creating new fields from existing data.
Step 6.4: Check the processed data for any remaining errors or inconsistencies.
Step 6.5: Finalize the processed data in preparation for analysis and calculation.
STEP#7: Data Analysis
Step 7.1: Define Analysis Goals—clearly define what you want to analyze and determine the most suitable GIS methods.
Step 7.2: Determine the appropriate property valuation method (market, cost, or income).
Step 7.3: Execute Analysis—Perform the GIS analysis using QGIS. This could include spatial analysis, network analysis, proximity analysis, etc.
Step 7.4: Expand analytics to consider using SQL with PostGIS to perform spatial queries, such as determining proximity to amenities or calculating parcel area.
Step 7.5: Use Python with libraries like numpy and scipy to perform mathematical calculations required for property valuation.
Step 7.6: Validate Analysis Results— Check the results of the GIS analysis to ensure they make sense and there are no errors.
Step 7.7: Store your results back in the geodatabase
STEP#8: Interpretation of Results

Step 8.1: Identify key insights from your analysis that need visualizing.
Step 8.2: Use QGIS for spatial data visualization, creating maps highlighting property values and other relevant data.
Step 8.3: Use Python with libraries like matplotlib or seaborn to create non-spatial charts and graphs. Also, as discussed in the open-source software tools, pandas can be used instead of numpy and scipy for data manipulation and analysis. Pandas provides various functions and methods that enable efficient data processing, cleaning, transformation, and analysis.
Step 8.4: Compile your visualizations into a report that presents your findings clearly and concisely.
Step 8.5: If intended, create a dashboard using open-source tools to visualize and present the property tax information and analysis results. Identify the specific requirements for the dashboard, considering the target audience and their needs. Choose an open-source dashboarding tool such as Grafana, Dash, or Apache Superset that aligns with your requirements. Connect the dashboarding tool to the data sources containing the property tax information, integrating databases, spreadsheets, or APIs. Design visually appealing and informative charts, graphs, tables, and maps using the dashboarding tool's features. Develop multiple dashboard panels or pages to display different aspects of the property tax analysis, arranging visualizations logically and intuitively. Customize the appearance and behavior of the dashboard, including color schemes, layout, filters, and interactive features. Test the functionality and usability of the dashboard, gathering feedback and refining it to improve effectiveness. Deploy the dashboard to a web server or hosting platform, ensuring appropriate access controls and permissions. Share the dashboard with stakeholders, enabling them to access and interact with the property tax information. Creating an open-source dashboard provides an interactive and visual representation of property tax analysis results, making it easier for stakeholders to interpret the data and make informed decisions.
Step 8.6: Interpret the analysis results in the context of set goals and objectives and action the insights from the analysis that can be used to inform property assessments and taxation policies.

STEP#9: Develop a Custom-Built GIS Application
Firstly, it's crucial to thoroughly understand the objectives of the Web/Mobile GIS application, the target audience, the type of data you'll be working with, and the specific features the end-users will need. Do they need to be able to interact with the data? If so, how? Should they be able to filter or search the data? Answering these questions upfront will help guide your design and development process. Don't rush this process or make assumptions about what the end users need. Communicate effectively with all stakeholders and consider getting their feedback at multiple stages throughout the project. There are really three building blocks to realizing a well-designed application: Block A—Setting Up the Geospatial Server: A geospatial server such as GeoServer or MapServer is needed to serve your geospatial data over the web, and finally, Block B—Designing the Web GIS Application: This phase involves planning and sketching the layout, functionalities, and overall user experience of the web or mobile application and creating a client-side Interactive Map Interface: This would require software like Leaflet, which is a powerful open-source JavaScript library for mobile-friendly interactive maps.
As discussed earlier, QGIS is a powerful GIS software that provides a wide range of data management, analysis, and visualization functionality. It can serve as both a content management system and an editor, allowing users or groups of users to interact with the data and obtain the desired results within the QGIS environment. However, there are cases where organizations may prefer to streamline the functionality of QGIS for specific purposes. For example, they may want to create a simplified interface for public-facing applications, where users only need to view data or perform limited data entry or editing tasks. In such cases, developing a custom-built GIS app that operates independently may be more suitable, providing a tailored user experience without direct interaction with QGIS. Similarly, organizations may build comprehensive GIS functionality into a web-based application for their internal users, allowing them to enter and access information seamlessly. This approach can provide a specialized interface that meets specific organizational needs while leveraging the power of GIS capabilities. In summary, depending on the requirements and target audience, organizations can either utilize QGIS directly or opt for custom-built GIS apps to present a subset or an enhanced version of the GIS functionality, ensuring a more tailored and user-friendly experience. This workflow step addresses when an organization opts for a special GIS app.
Black A—Setting Up the Geospatial Server
1. Installation of GeoServer: A GeoServer is a Java-based software server that allows users to view and edit geospatial data. Using open standards set by the Open Geospatial Consortium (OGC), GeoServer allows great flexibility in map creation and data sharing. GeoServer's capabilities extend to on-the-fly rendering of geospatial data to images for visualization on a map, making it easier to depict intricate geographic data within your application. Moreover, it's designed for performance and scalability, which makes it well-suited for high-demand scenarios, offering options for caching and clustering. While it's possible to create a web or mobile app without a GeoServer if your app requires interaction with intricate geospatial data, geographic queries, or rendering geospatial data on a map, it can simplify and optimize these tasks. There are several open-source geospatial servers available. We discussed them above. GeoServer is perhaps the most popular open-source server designed to serve geospatial data. MapServer is another popular open-source platform for publishing spatial data and interactive mapping applications to the web. It's known for its speed and reliability. We can go with PostGIS, which, while technically an extension to the PostgreSQL database, PostGIS adds geospatial capabilities to the database, effectively allowing it to serve as a geospatial data server. It's particularly known for its powerful spatial database capabilities. To start with the installation, first, ensure that you have Java installed on your system. GeoServer requires a Java Runtime Environment (JRE), and it's recommended to use a version that GeoServer officially supports. Download and install GeoServer from the official website. The installation process is relatively straightforward, with installers available for various operating systems. After installation, you can start GeoServer by running the startup script that came with the installation. This will launch GeoServer, which by default runs on port 8080. By navigating to http://localhost:8080/geoserver, you can access the GeoServer web admin interface to start managing your geospatial data.
Do: When installing and setting up GeoServer, there are some important do's and don'ts to consider. Always ensure that your system meets the requirements to run GeoServer effectively. Using the latest stable version of GeoServer is advisable for optimal performance and up-to-date features. During installation, remember to keep track of the administrator username and password you set, as this is crucial for managing your server.
Don’t: On the other hand, there are certain practices you should avoid. Do not forget to check if the necessary ports, by default 8080, are open and not being used by other applications, as this could cause conflicts. Lastly, you must avoid using an unsupported version of Java, which could lead to instability or failure in running GeoServer.
Output: At the end of this step, you should have a running instance of GeoServer that you can access through your web browser at http://localhost:8080/geoserver (or replace 'localhost' with your server's IP if you're running GeoServer on a remote server).
2. Configuration of GeoServer: Configuring GeoServer involves setting up workspaces, adding data stores, and publishing layers. A workspace in GeoServer is a logical grouping of data. You might create a workspace for each project or department in your organization. For instance, you could create a workspace named "ParcelsTax" for all parcel tax-related data. A data store is a repository of spatial data. This could be a PostGIS database, shapefile, or GeoTIFF raster file. You would create a data store for each source you want to serve. To add a data store, go to the GeoServer admin interface, select the workspace you want to add the data store too, then click "Add new Store". You'll need to provide the connection parameters to your PostGIS database, path to your shapefile, or other data source. Once a data store is added, you can publish layers from it. A layer is a set of spatial data that can be displayed on a map. It could represent roads, buildings, or any other geospatial feature.
Do: For managing GeoServer; it's important to do the following: Use descriptive names for your workspaces, data stores, and layers to enhance manageability, ensure that you validate your data store connection before saving, and set the Coordinate Reference System (CRS) for your layer, typically to EPSG:4326 for geographic coordinates or EPSG:3857 for Web Mercator which is commonly used in web mapping.
Don’t: However, there are certain actions you should avoid: Do not leave layers without a defined bounding box, as GeoServer can compute this automatically from your data, and remember not to forget to enable the layer after you publish it.
Output: You should now have GeoServer configured with at least one workspace, data store, and published layer. Your geospatial data is now available through web services like WMS and WFS. You can view your layer by going to the "Layer Preview" section in the GeoServer admin interface.
3. Securing GeoServer: GeoServer has extensive security configurations. It is crucial to secure your GeoServer instance, especially if it is accessible over the internet. GeoServer’s security system provides authentication and authorization services, allowing you to control who can access the server and what they can do. Ensure the admin password has been changed from the default for basic security. GeoServer’s admin interface also allows setting up users and roles, providing more granular access control. Additionally, you may want to set up data security, which allows you to control access to individual layers. For example, you could restrict sensitive layers to be accessible only by certain users or roles. GeoServer also supports Secure Socket Layer (SSL), allowing for encrypted communication between the server and clients.
Do: For GeoServer, it's important to change the default admin password, use strong, unique passwords for all users, regularly update user access, and set up SSL for secure communication.
Don’t: On the contrary, you should avoid leaving the admin interface accessible to the public with the default password and refrain from granting excessive permissions to any user or role.
Output: You should now have a secure GeoServer instance with users and roles configured, and your layers should have appropriate access restrictions. You've also ensured secure communication between your GeoServer instance and clients.
4. Styling Layers in GeoServer: Styling in GeoServer is achieved using Styled Layer Descriptor (SLD), a standard developed by the Open Geospatial Consortium (OGC). SLD uses XML to describe how a map layer should look. GeoServer has a basic set of styles, but you can also create your own. To create a style, go to the "Styles" section of the GeoServer admin interface and create a new style. You can write your own SLD in the provided text box or upload an SLD file. After creating a style, you can apply it to a layer by editing its settings and selecting your new style as the default.
Do: Use descriptive names for your styles and test them before applying them to a layer.
Don’t: Don't use complex styles that could slow down the rendering of your layers.
Output: You should have styled layers that can be served as maps using GeoServer's Web Map Service (WMS). These can be previewed in the "Layer Preview" section in the GeoServer admin interface.
5. Testing and Debugging GeoServer: To ensure that GeoServer functions correctly, you can use the built-in demos and the "Layer Preview" functionality. The "Layer Preview" page lists all available layers and lets you view them in various formats. For more extensive testing and debugging, GeoServer's logging can be configured to provide more detailed logs. The log level can be set to GEOTOOLS_DEVELOPER_LOGGING, GEOSERVER_DEVELOPER_LOGGING, or PRODUCTION_LOGGING, depending on your needs.
Do: Regularly test your layers and services to ensure they function correctly and use the appropriate logging level for your needs.
Don’t: Don't leave GeoServer set to a verbose logging level in a production environment, as it may affect performance.
Output: A well-tested, functional, and optimized GeoServer is ready to serve your geospatial data to client applications. Once GeoServer is set up, the next step would be to integrate it with Leaflet, which we've already discussed in the previous workflow.
Black B—Designing the Web GIS Application with Leaflet - An In-Depth Guide
1. Brainstorming/Outlining the Web GIS Application: This involves knowing the objectives of the Web GIS application, the target audience, the type of data you'll be working with, and the specific features the end-users will need. Do they need to be able to interact with the data? If so, how? Should they be able to filter or search the data? Answering these questions upfront will help guide your design and development process. This step involves a general understanding of the planning and sketching of the web or mobile application's layout, functionalities, and overall user experience. It's where you define what the application will do, how it will present information, and how users will interact. Will it display static maps or dynamic, interactive maps? Can users perform spatial queries, add or edit or view data? How will the data be symbolized, and what navigation and search options will be provided? Depending on your target audience, you may also want to consider accessibility features. This provides a high-level understanding rather than a detailed design, but it's beneficial to grasp what the app intends to do before delving into the specifics. One thing that is good to get at least identified here is what software you will use or the client-side map interface. Here, we have chosen Leaflet.
2. Get to know the software tool right: Once you clearly understand what you need to achieve, you'll need to ensure the right tools are ready to do the job for you, which only happens when you know the tool well. Leaflet is a fantastic choice for creating interactive maps, but you might also need additional tools or libraries to fulfill your specific project requirements. For instance, you may use Leaflet plugins like Leaflet.draw for drawing and editing geometric shapes or Leaflet.markercluster for handling large amounts of markers.
3. Planning the Map Layout: Next, you'll need to plan the layout of your map. This includes deciding on the initial view (i.e., the geographical area users will see when they first load the map), the zoom levels, and the positioning of controls like zoom buttons and layer switchers. Another important aspect of the map layout is the base map, which provides the geographical context for your data. Leaflet supports a variety of base maps, from popular options like OpenStreetMap and Google Maps to more specialized ones like Stamen's artistic Watercolor or Toner maps. When choosing a base map, consider the overall design of your application and what kind of visual impression you want to make.
4. Designing the Data Visualization: The next step is to design how your data will be visualized on the map. This includes choosing the right kind of map elements (markers, lines, polygons, etc.), their colors, and their styles. If you have a large amount of data, you might consider clustering or using heat maps. You'll also need to decide how users can interact with the data. For instance, you might use popups to display more information when a user clicks on a marker or a polygon. Or, you might enable users to filter the data based on certain criteria.
5. Ensuring Mobile Compatibility: You must ensure your map works well on mobile devices. This involves ensuring that the map and its controls are large enough to be easily used on a small screen and that any popups or other interactive elements work smoothly with touch controls.
Do: Keep the user in mind while designing the application. Functionality is important, but so is user experience. The application should be intuitive and easy to use. Do spend enough time on this initial stage, as understanding the app will set a solid foundation for the subsequent design and development stages. In crafting your map application, it is crucial to follow certain guiding principles. Begin by investing ample time in the initial stage, as a thorough understanding of the project requirements sets a robust base for future design and development stages. Also, ensure the tools and libraries chosen align well with your project needs and are compatible with Leaflet, well-documented, and actively maintained. Keeping the end-user in mind, design a map layout that is intuitive and visually pleasing. When designing the data visualization, clarity and effectiveness should be your main focus; use distinguishable colors and styles, and ensure users can comprehend the data representation. Lastly, guarantee a smooth user experience across all platforms by testing your map on various devices and screen sizes.
Don’t: Conversely, there are practices you must steer clear of. Never rush the initial process or make assumptions about the end-users needs, and remember to effectively communicate with all stakeholders, obtaining feedback throughout the project. Refrain from using a tool or library merely because of its popularity or trendiness; ensure it fits your specific project needs best. A crucial element not to overlook is the base map; it forms the foundation of your application and significantly influences the user experience. Avoid overloading the map with data, as excessive information can overwhelm and confuse users. Don't try to cram too many features into the application simultaneously. It's better to start with a few essential features and gradually add more based on user feedback. Don't rush this process or make assumptions about what the end users need. Communicate effectively with all stakeholders and consider getting their feedback at multiple stages throughout the project. Lastly, never assume that what functions well on a desktop will perform equally well on a mobile device; be prepared to adapt to the nuances of different platforms.
Output: The output of this step is a detailed plan for your Web GIS application, including the chosen tools and libraries, the map layout, the data visualization design, and the plan for ensuring mobile compatibility. This plan serves as the blueprint for the development phase, where you'll translate your design into code. This extensive preparation and planning are crucial to developing a successful Web GIS application that meets the needs of its users and provides an intuitive and effective way to interact with geospatial data.
6. Developing the Web GIS Application: With your detailed plan in place, you can now begin the actual development of the application. Start by setting up your development environment. This might include installing Node.js and npm (Node Package Manager) and your chosen text editor or Integrated Development Environment (IDE). You'll also want to install Leaflet and any other libraries or plugins you plan to use. Next, you must create your HTML, CSS, and JavaScript files. The HTML file will provide the structure of your application, the CSS file will control the appearance, and the JavaScript file will contain the functionality. Begin by creating the basic structure of your application in your HTML file. This might include a map container (where your map will be displayed) and other elements like headers, footers, sidebars, or control buttons. Next, use CSS to style your application. This might involve setting the size of your map container, choosing colors and fonts, and positioning any additional elements. Once your application looks how you want it to, you can add functionality with JavaScript and Leaflet. Start by initializing a map in your map container and setting the initial view and zoom level. Then, add your base map. Next, load your data and add it to the map. Depending on the type of data and your design plan, this might involve adding markers, lines, polygons, or other map elements. You might also add popups or other interactive elements at this stage. Finally, test your application thoroughly, both on desktop and mobile devices. Make sure all functionality works as expected, and fix any bugs you find. Without digging too much into the coding side of things a few recommendations are worthy of mention:
(a) Node.js and npm (Node Package Manager: Node.js is a JavaScript runtime that allows developers to run JavaScript code on the server side. Traditionally, JavaScript was a client-side, run in the web browser. However, with Node.js, JavaScript can be executed on the server side, enabling fast and scalable network applications to be built. It is built on Google Chrome's V8 JavaScript engine, making it very efficient and capable of handling multiple simultaneous connections with high throughput. It makes it perfect for building web servers and RESTful APIs. npm (Node Package Manager) is a package manager for the JavaScript programming language. It is the default package manager for Node.js. npm is used to install Node.js programs from the npm registry, organize the installation, and manage the various dependencies of the program. Node.js and npm are necessary for the GIS web GIS development, especially in the context of using a library like Leaflet: (1) Package Management: npm simplifies the process of installing and managing the various libraries, frameworks, and tools you'll use in your web application, such as Leaflet itself and any plugins or extensions you may use with it. This is critical in large applications where managing dependencies manually would be too complex and error-prone; (2) Development Tools: Many tools used in modern web development, such as build systems or JavaScript module bundlers like Webpack or Rollup—take your JavaScript application, which can include numerous individual JavaScript files and dependencies, and package them into one or more bundle files that can be loaded in a web browser, testing frameworks, code linters—tools used in programming to analyze source code for potential errors and bugs, and others are built to run on Node.js. These tools help streamline and automate the development process, making developers more productive and helping ensure code quality; (3) Server-Side Rendering (SSR): Node.js enables server-side rendering of web applications, which can improve performance and SEO. While not necessarily applicable to all Leaflet applications—Leaflet primarily operates on the client side, SSR might be a key requirement if you're building a larger web application that includes a map, among other features, and (4) Building APIs: If your web application needs a custom backend for handling application data or complex server-side logic, Node.js is a popular choice for building this. Several powerful frameworks like Express.js can simplify this process.
(b) Text Editor or Integrated Development Environment (IDE): Choosing the right text editor or Integrated Development Environment (IDE) is a critical step in setting up your web GIS application development environment. A good IDE will support your coding habits, increase efficiency, and allow seamless integration with other tools. Visual Studio Code (VS Code) is a free, open-source text editor developed by Microsoft that supports a variety of languages, including HTML, CSS, JavaScript, Node.js, and features debugging tools, Git commands built-in, intelligent code completion (IntelliSense), and a robust marketplace for extensions to enhance its capabilities further. For GIS development, extensions such as "ESLint" (a popular open-source static code analysis tool for JavaScript used to identify and report patterns or code practices that may have errors or could lead to potential bugs, maintainability issues, or inconsistencies in the codebase) could help in maintaining clean, error-free JavaScript code. For a more fully-featured IDE, JetBrains WebStorm could be a good choice. Although it's a paid product, it's highly regarded for its powerful features, such as on-the-fly error detection, smart code completion, robust navigation, and refactoring tools. It also has a built-in terminal and supports Node.js, which will benefit your GIS application development.
Do: Use version control (like Git) to track your changes and allow easy collaboration and debugging. Also, remember to test your application regularly during the development process so that you can catch and fix bugs early.
Don't: Don't let perfection be the enemy of progress. It's okay if your application isn't perfect the first time around - what's important is that it works and meets the needs of its users. You can always refine and improve it over time.
Output: The output of this stage will be the functional Web GIS application, ready for deployment. It will incorporate your planned design, data visualization, and user interaction elements and will be compatible with desktop and mobile platforms.

STEP#10: Deployment and Maintenance
The operation and enhancement of Geographic Information System (GIS) applications consist of three main sections. Block A—Initial Deployment and Maintenance includes preparing, testing, configuring, and deploying the application. User training is provided for effective usage, and regular updates, maintenance, and data backups are carried out to ensure the system's smooth operation and data protection. Block B—Ongoing Data Management and Updates focus on maintaining data quality through regular validation and maintenance. Archiving and versioning preserve data integrity, while access control policies and performance optimization safeguard data security and enhance the application's user-friendliness and functionality. Finally, Block C—Evaluation and Improvement emphasizes the iterative process of user feedback collection, performance evaluation, and improvement implementation. Impact assessment ensures the effectiveness of these changes, and this cycle, when repeated regularly, allows for continuous improvement, keeping the GIS application dynamic, efficient, and responsive to user needs. Throughout all stages, user feedback is highly valued, regular evaluations are conducted, necessary improvements are implemented, and there is a constant strive for continuous enhancement.
Block A--Initial Deployment and Maintenance
1. Prepare for Deployment: The preparation phase for deployment is critical for ensuring the application is ready for use in the desired environment. It involves thorough testing to identify and fix any potential bugs or errors that may impair functionality. Debugging involves a systematic process to isolate the source of the problem and correct it, improving the stability and performance of the application. It's also important to configure any settings necessary for the deployment environment. This might involve adjusting security settings, database connections, or other server-related configurations to match the specifications of the deployment environment.
2. Deploy the Application: Deploying the application involves installing it on the intended web server, a local server or a cloud-based server like AWS or Google Cloud. The process usually involves transferring the application files to the server, setting up the necessary database connections, and adjusting server settings to accommodate the application. Cloud-based servers are becoming increasingly popular due to their scalability, reliability, and relatively low maintenance requirements.
3. User Training: End-user training ensures users can utilize the GIS application effectively. This involves teaching them how to interact with the map, execute queries, and interpret the results. Training can take various forms, such as in-person workshops, online tutorials, or user manuals. The goal is to equip users with the knowledge and skills to use the application effectively and efficiently.
4. Regular Maintenance and Updates: Maintaining the GIS application continuously ensures its smooth operation. This involves regularly updating the GIS data, fixing any bugs that may arise, and improving features based on user feedback. Updating GIS data ensures users can access the most recent and accurate information. Bug fixes enhance the application's stability, while feature improvements enhance its usability and functionality.
5. Regular Backups: Regular backups are essential for data protection and disaster recovery. This involves creating copies of the application and the GIS database at regular intervals and storing them in a secure location. In the event of a system failure or data loss, the backup can be used to restore the application and the database to its previous state, minimizing downtime and data loss.
Do: Strive for a simple, intuitive user interface that encourages interaction. Provide clear instructions and resources to help users navigate the application. Maintain a regular update and maintenance schedule to ensure smooth operation. Back up the application and the GIS database regularly to safeguard your data. Prioritize the privacy and security of user data.
Don't: Skip thorough testing before deployment, as undetected bugs can impact user experience. Disregard user feedback, as it can offer valuable insights for improving the application. Neglect the importance of regular backups, as they are critical for disaster recovery. Forget providing adequate user training, as it's essential for effective application use. Overlook the privacy and security of user data, as these are paramount in maintaining user trust.
Block B—Ongoing Data Management and Updates
1. Data Validation and Quality Assurance: Effective GIS applications require high-quality data. Consistently checking for data accuracy, completeness, consistency, and adherence to set standards is crucial for the application's success. Validation ensures the data inputs into the GIS are accurate and reliable. Quality assurance helps maintain a high data standard by eliminating errors, inconsistencies, and duplicates.
2. Data Updates and Maintenance: Regular data updates ensure that the most recent and accurate information is available for users. This could include updated property assessments, tax rates, or changes in spatial data. Regular maintenance, such as resolving data conflicts, updating metadata, and checking the integrity of the data, is necessary to keep the application running smoothly and reliably.
3. Data Archiving and Versioning: Archiving data provides a historical reference that can be useful for tracking changes over time and future analyses. Versioning also allows for the tracking of changes by saving different iterations of data. Archiving and versioning help maintain data integrity and enable comprehensive trend analysis and comparability.
4. Data Security and Access Control: Data security is paramount to protect sensitive information and maintain user trust. Defining access control policies and restrictions based on user roles and permissions helps to safeguard data and prevent unauthorized access. Proper data security measures help uphold the confidentiality and integrity of the data.
5. Performance Monitoring and Optimization: Regularly monitoring the performance of the GIS application and the underlying database is necessary to ensure optimal functionality. Identifying areas for optimization, such as query performance, indexing, and resource utilization, can lead to improvements in data retrieval and analysis. Monitoring can help identify bottlenecks and areas for improvement, ensuring the application remains efficient and user-friendly.
Do: Consistently validate and update the data to maintain its accuracy and quality. Regularly archive and version your data to maintain historical records. Prioritize data security and define strict access control policies. Regularly monitor the performance of the application and database and optimize as necessary.
Don't: Neglect regular data validation, as outdated or inaccurate data can lead to erroneous analyses. Overlook the importance of data security and user access controls, which are critical for maintaining user trust. Ignore performance monitoring and optimization, which are crucial for maintaining a user-friendly and efficient application. Disregard the importance of data archiving and versioning, as these practices help maintain data integrity and enable comprehensive analyses.
Block C—Evaluation and Improvement
1. User Feedback Collection: User feedback is a vital resource for the continuous improvement of the GIS application. This feedback can be collected through various methods, such as surveys, forums, or direct communication. Understanding users' experiences, difficulties, and preferences can offer invaluable insights into potential modifications, additions, or eliminations within the application to enhance user satisfaction and utility.
2. Performance Evaluation: Systematic evaluation of the GIS application performance is key to its success. This evaluation involves assessing both technical and practical aspects. Technically, metrics like load times, error rates, response times, and uptime can be evaluated to ensure the application is technically sound and efficient. On a practical level, the usability of the interface, accuracy of the map data, user satisfaction, and utility of the application should be evaluated to ensure the application serves its intended purpose effectively.
3. Improvement Implementation: Based on the collected user feedback and the results of performance evaluations, improvements to the GIS application can be planned and implemented. Improvements might include refining the user interface, adding new features, optimizing underlying data models, or enhancing the server setup. These changes should ideally lead to a more robust, user-friendly, and efficient GIS application that better meets the users' needs.
4. Impact Assessment: Post-implementation, assessing the impact of the changes made is important. This involves re-evaluating the performance metrics and user feedback to identify whether the modifications have brought the desired improvements. This step ensures that changes positively affect the application and its users and helps identify further areas for improvement.
5. Continuous Improvement: Continuous improvement involves repeating this cycle—feedback collection, performance evaluation, improvement implementation, and impact assessment—regularly. This approach ensures that the GIS application remains dynamic, responsive to users' needs, and continually strives for better performance and usability.
Do: Regularly seek and value user feedback, evaluate performance, implement necessary improvements, assess the impact of changes, and uphold a culture of continuous improvement.
Don't: Dismiss user feedback, as it offers valuable insights for improvement. Ignore the importance of regular performance evaluation, as it provides the basis for identifying necessary improvements. Neglect the implementation of improvements, which is key to maintaining a high-quality, user-friendly GIS application. Overlook the assessment of the impact of changes, as this step validates the effectiveness of improvements. Fall into complacency—instead, always strive for continuous improvement to keep your GIS application at its best.
Go back to Part 1 here.
This article offers a detailed examination, from the lens of software engineering and coding, of a case study on the use of Geographic Information Systems (GIS), Workflows, Open-Source Software, Application Areas, and Spatial Data Infrastructure (SDI) within the scope of municipal finance. We crafted this to help our client's engineering teams grasp the wide array of possibilities and the subtleties of integration. We aim to provide a succinct yet exhaustive overview that avoids excessive complexity while shedding light on the infrastructures, applications, and use cases we frequently champion in our solution delivery. OHK often uses GIS and SDI in its planning and analytics work; contact us if you want to learn more about this work.